 |
| ASCII�R�[�h |
|
| ASCII�R�[�h |
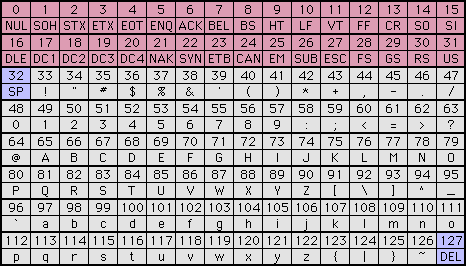 |
| ASCII�R�[�h |
|
| ISO 646�i�\����ASCII�R�[�h���̂��́j |
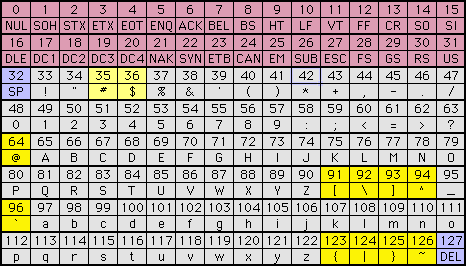 |
| ISO 646�iIRV�j |
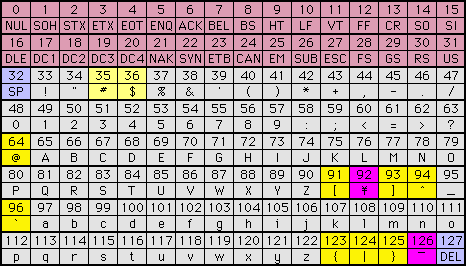 |
| ISO 646���{��� |
 |
| �g��7�r�b�g�R�[�h |
 |
| ISO 8859 |
| �o�[�W���� | ���� | �ʖ� | ���l |
|---|---|---|---|
| ISO-8859-1 | �������e���� | Latin1 | �@ |
| ISO-8859-2 | �������e���� | Latin2 | �@ |
| ISO-8859-3 | �쉢���e���� | Latin3 | �G�X�y�����g�� |
| ISO-8859-4 | �k�����e���� | Latin4 | �@ |
| ISO-8859-5 | �L�������� | �@ | ���V�A�� |
| ISO-8859-6 | �A���r�A�� | �@ | �@ |
| ISO-8859-7 | �M���V���� | �@ | �@ |
| ISO-8859-8 | �w�u���C�� | �@ | �@ |
| ISO-8859-9 | �g���R�� | Latin5 | �@ |
| ISO-8859-10 | �k�����e���� | Latin6 | Latin4�̉����� |
| ISO-8859-11 | �^�C��i�\��j | �@ | �@ |
| ISO-8859-12 | �C���h��i�\��j | �@ | �@ |
| ISO-8859-13 | ���g�r�A�� | Latin7 | �@ |
| ISO-8859-14 | �P���g�� | Latin8 | �@ |
| ISO-8859-15 | �������e���� | Latin9 | Latin1�̉����Łi��L����lj��j |
| ISO-8859-16 | �������e���� | Latin10 | Latin2�̉����� |